Prompt Engineering Guide
Table of Contents
Introduction
What are “Prompt Engineers”? At first, you might think that prompt engineering isn’t really “engineering”— perhaps it’s just today’s version of a “Professional Googler.” But after working on building Generative AI applications for about two years, I’ve come to realize there’s much more to crafting prompts than using a few tricks or keywords.
Prompt engineering directly impacts the effectiveness, accuracy, and safety of Large Language Models (LLMs) like ChatGPT. As these models get integrated into everything from customer service to content creation and decision-making, prompt engineering ensures they perform reliably and efficiently.
Basics of Large Language Models (LLMs)
What is an LLM?
Before we dive into prompt engineering, it’s helpful to first understand the basics of how LLMs work. At their core, LLMs use neural networks, which process inputs through layers of interconnected nodes. These networks perform complex calculations to generate predictions, which ultimately help the model determine what comes next in a sequence. This process is key to understanding how prompts shape the model’s output, as we’ll explore in more detail.
 Source: emmanuelogebe.hashnode.dev
Source: emmanuelogebe.hashnode.dev
How do LLMs work?
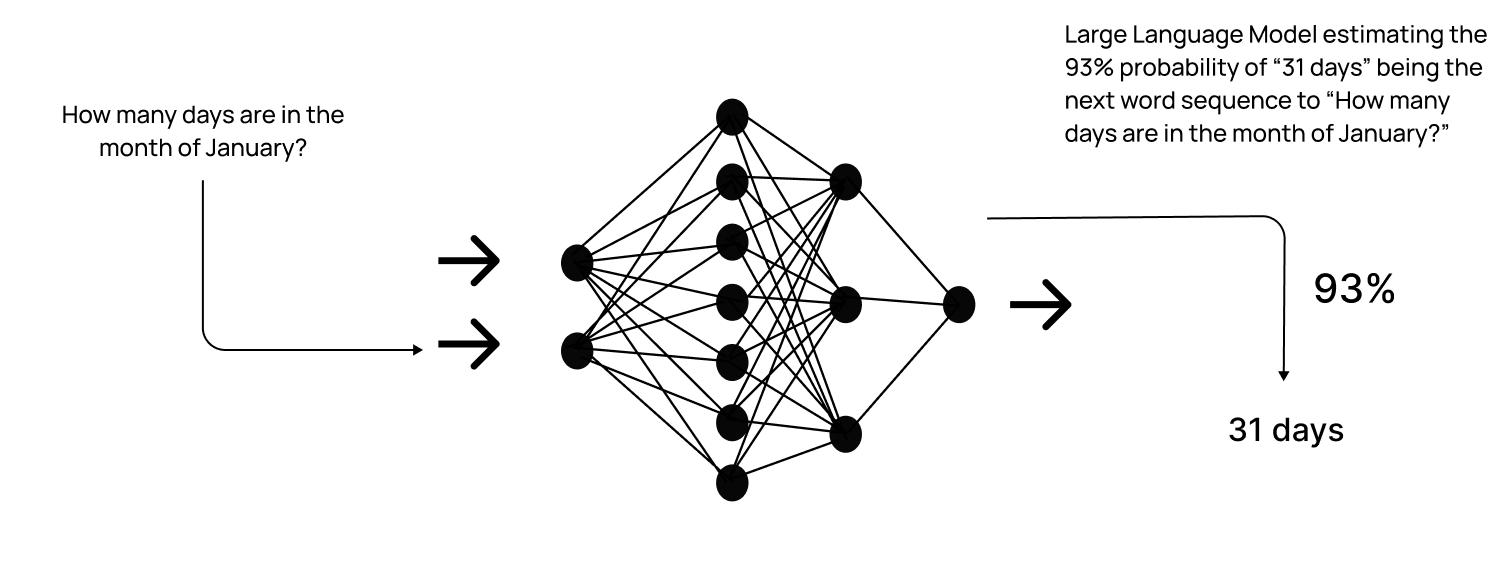
Diving deeper, these calculations essentially work to predict the next word or token based on the input. For example, when the input is, “How many days are in the month of January?” the model predicts “31 days” with a 93% probability. It’s important to note that “31 days” isn’t a single word, but a token—a unit of text that can represent a word, phrase, or even punctuation. LLMs break down text into these tokens to process and generate responses more efficiently.
 Source: emmanuelogebe.hashnode.dev
Source: emmanuelogebe.hashnode.dev
Building an LLM for a Specific Use Case
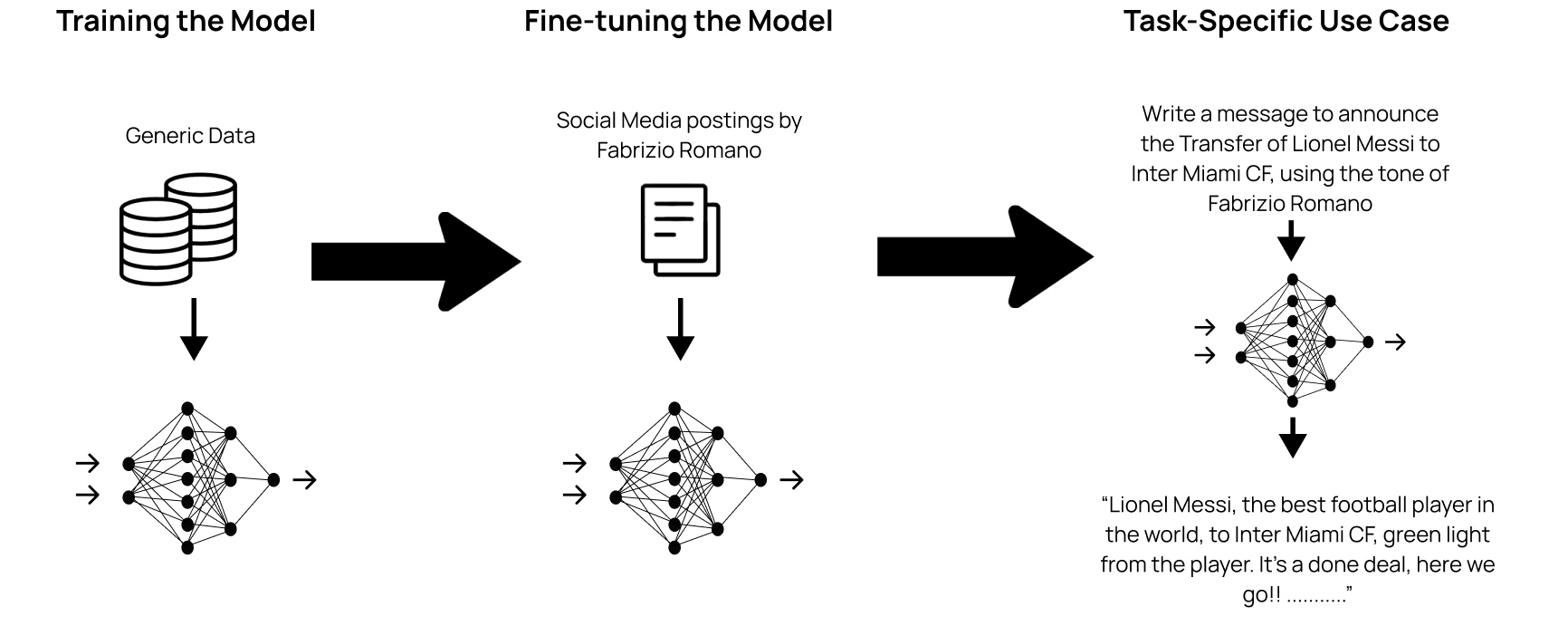
Building an LLM for a specific use case involves three main steps. First, the model undergoes pre-training, where it learns the basics by processing large amounts of generic data, such as articles, books, and forum posts from the Internet. This is how the model grasps the fundamentals of human language and writing.
Next, the model is fine-tuned for a particular use case. For example, by training it on social media posts by Fabrizio Romano, the model learns his tone and style. Finally, the fine-tuned model can be used to generate messages that mimic Fabrizio Romano’s voice, tailored to that specific use case.
 Source: emmanuelogebe.hashnode.dev
Source: emmanuelogebe.hashnode.dev
Temperature in LLMs
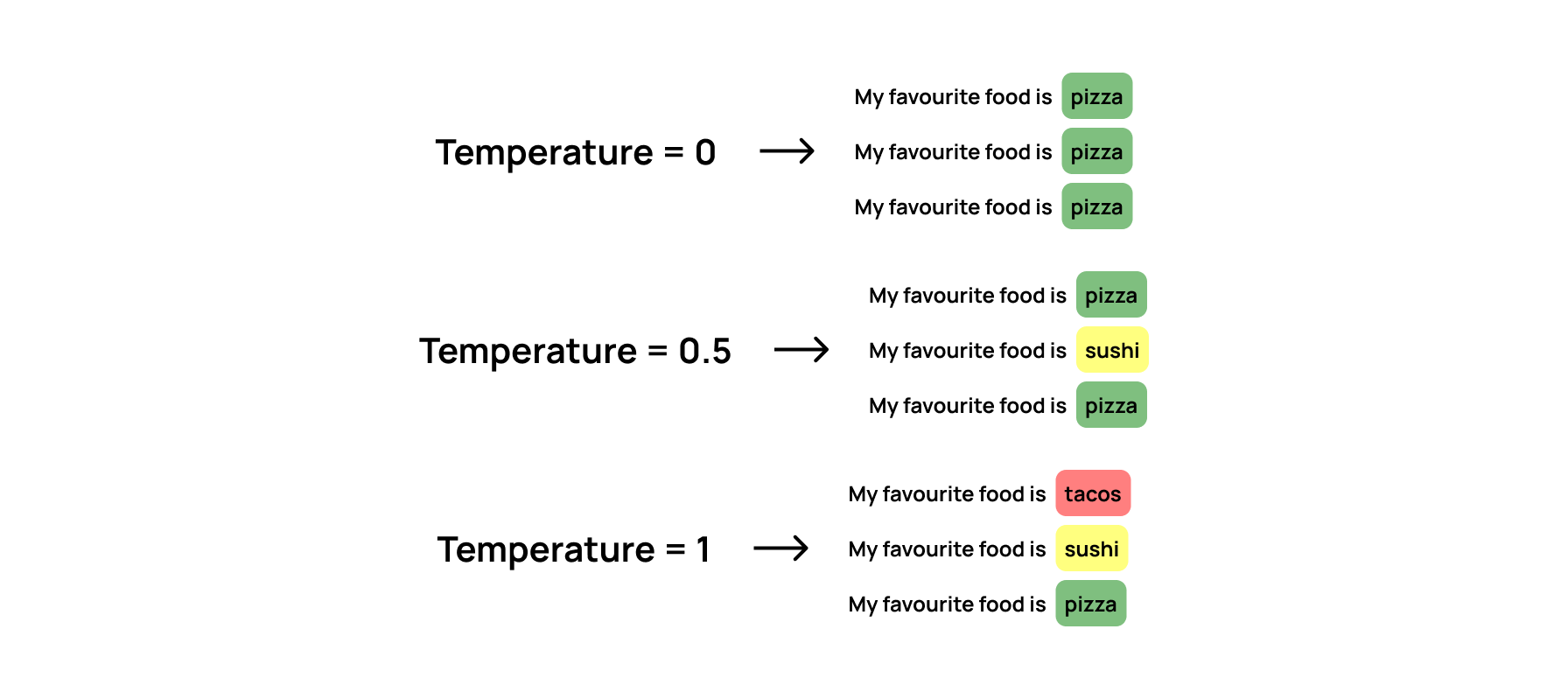
One of the key adjustments available in any prompt playground is temperature – a float value ranging from 0 to 2.0.
Going back to how LLMs work, they try to predict the next word (or more specifically, the next token). During this prediction, the next prediction consists of a series of words with different confidence levels.
Using the below example, the word following “My favourite food is” can be pizza (53% confidence), sushi (30% confidence) or tacos (5% confidence).
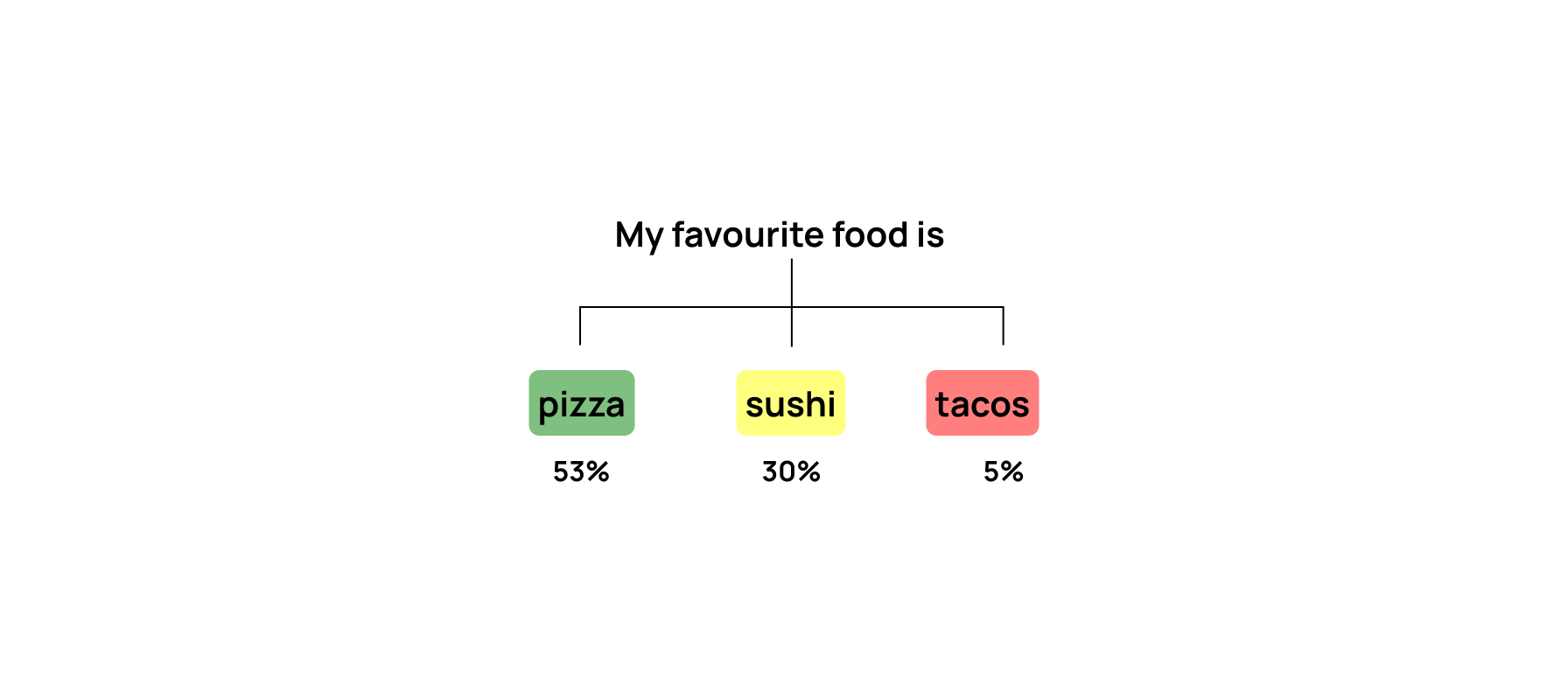 Temperature controls the randomness of the models’ output. A lower temperature makes the output more deterministic, favoring more likely words, while a higher temperature allows for more creativity by considering less likely words
Temperature controls the randomness of the models’ output. A lower temperature makes the output more deterministic, favoring more likely words, while a higher temperature allows for more creativity by considering less likely words
Prompt Playgrounds
There are a lot of tools to be able to try and test different prompt. Two useful tools that I have tried and work in Hong Kong are:
- Vercel’s AI Playground – Allows you to compare the prompt across different models.
- Groq Cloud Playground – Allows you to test with models supported on Groq (Meta Llama and more).
Prompt Structuring
Simplest Structure
The simplest prompt consists of just the direct prompt to the LLM.
prompt = “Hi ChatGPT, how are you?”
#Print Response
response = llm.invoke(prompt)
print(response.content)
System Message and User Messages
A better way we can divide the base instructions to the LLM from the user’s prompt is to use Messages.
Messages consist of a list (think of it like a chat history). The two types of messages that are relevant to Prompt Engineers are 1) System Messages and 2) User Messages.
System Messages are instructions on the broad task that you’re using the model for, and generally have more weight for the model.
User Messages are instructions from the user for the specific question that the user has.
prompt = “Hi ChatGPT, how are you?”
#Print Response
messages = [
{"role": "system", "content": "You are a helpful assistant that provides guidance to five year olds."},
{"role": "user", "content": prompt}
]
response = llm.invoke(messages)
print(response.content)
Being Clear and Direct
One key tip to get your AI-application to seem more professional is to remove the preamble the model has, for example: “Sure, here is a poem about…”. This is so that the user receives only what they ask for and nothing else.
prompt = “Write a haiku about robots. Skip the preamble; go straight into the poem.”
#Print Response
response = llm.invoke(prompt)
print(response.content)
Assigning Roles
Another way to get output that is more in-line with what the user expects, is to assign the model a role. For example, in an educational chatbot for kids, you can prompt the AI to think like a kindergarten teacher, ensuring the output is appropriate for kids.
# No Role
prompt = “What do you think about skateboarding?”
#Print Response
response = llm.invoke(prompt)
# With Role
prompt = “What do you think about skateboarding?”
#Print Response
messages = [
{"role": "system", "content": "You are a cat."},
{"role": "user", "content": prompt}
]
response = llm.invoke(messages)
Section Separators
As our prompts get more complex, especially with reference materials or examples, it can get difficult for the model to tell where the results are.
XML Tags
<instructions> Here are the instructions </instructions>
<evidence> Reference this </evidence>
Markdown
#### Instructions
Here are the instructions
#### Evidence
Reference this
Commas Commas can be a quick way to separate evidence if the prompt only has two sections.
I am Devansh, help me reply to the following email.
“““
Dear Devansh
....
”””
Please be concise.
Prompt Templates
Prompts don’t necessarily have to be static, and instead can be generated using prompt templates, taking into account input from the user.
prompt = “What do you think about skateboarding?”
#Print Response
messages = [
{"role": "system", "content": "You are a cat."},
{"role": "user", "content": prompt}
]
response = llm.invoke(messages)
print(messages)
Compiled Prompt:
[
{"role": "system", "content": "You are a cat."},
{"role": "user", "content": “What do you think about skateboarding?”}
]
Example – Notion AI
An example of this can be Notion AI, where you simply select text, and click a button to improve writing.
The underlying prompt template might look something like this:
# Selected Text
selected_text = “
LLMs sometimes mess up with the order of options. They usually pick the second one, probably because when they were trained, the second choice was right more often. You can fix this by putting the thinking process in XML tags.”
# Prompt Template
prompt = f“““
<instructions>
Help improve the writing of the following sentence of the user.
</instructions>
<text>
{selected_text}
</text>
”””
#Print Response
messages = [
{"role": "system", "content": "You are an expert at grammar, and will help the user make changes according to their requirements. Skip the preamble, only provide the adjusted answer. Wrap the answer in XML tags <answer></answer>"},
{"role": "user", "content": prompt}
]
The output result from the model might look something like this:
<answer>
LLMs are sometimes sensitive to ordering. In most situations, LLMs are more likely to choose the second of two options, possibly because it its training from the web, second options were more likely to be correct. This can be fixed by wrapping the thinking in XML tags.
</answer>
Chain of Thought (CoT)
Think of the following problem, and how you would solve it.
Rodger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does have have now?
It might seem obvious that the answer is 11, but you probably went through the following steps to solve the problem.
He started with 5 balls.
Each can of tennis balls has 3 balls.
Rodger bought 6 more tennis balls. (2 x 3 = 6)
So Rodger has a total of 5 + 6 = 11 tennis balls.
However, when you ask an LLM, it simply tries to predict the next word, which might just be a random number. To solve this issue, CoT prompting can be used to enable the AI to break-down the problem and have a better result.
# Prompt
prompt = “““
<question>
Rodger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does have have now?
</question>
<instructions>Let’s think step by step. Wrap your thoughts in <thoughts></thoughts> tags and your answer in <answer></answer></instructions><thoughts>
”””
#Print Response
response = llm.invoke(prompt)
print(response.content)
Emerging Models
Recently OpenAI has launched a series of models o1, that use CoT by default for better reasoning. A warning is that OpenAI specifically asks to avoid CoT prompting with this model to avoid unnecessary processing.

Few-Shot Prompting (i.e. Using Examples)
Another way to ’teach’ the LLM how to solve a problem in a certain way without fine-tuning the model is to show the model a few examples.
# Prompt:
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is:
We were traveling in Africa and we saw these very cute whatpus.
To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses the word farduddle is:
# Response:
When we won the game, we all started to farduddle in celebration.
Avoiding Hallucinations
Hallucinations are when LLMs produce misleading, factually incorrect, or entirely fabricated responses.
Providing the LLM with an ‘Exit Option’
Going back to how LLMs work, they simply predict the next token. When the prompt does not give the LLM an option to answer ‘I don’t know’, the LLM will give the user a response confidently, even if it is completely wrong.
Example without Exit Option Here, when the LLM is asked explicitly being told to answer ‘I don’t know’ unless it is absolutely certain, it hallucinates and gives a non-sensical response.
# Prompt:
Who is the heaviest hippo of all time?
# Response:
The answer is: Donald the hippopotamus.
Donald the hippopotamus was the heaviest hippopotamus ever recorded, weighing in at 20,000 pounds.
Example with Exit Option Here, we can see that when the LLM is provided with an ’exit option’, the prompt is able to successfully reduce hallucinations.
# Prompt:
Who is the heaviest hippo of all time? Only answer if you know the answer with certainty.
# Response:
The answer is: Donald the hippopotamus.
Donald the hippopotamus was the heaviest hippopotamus ever recorded, weighing in at 20,000 pounds.
Using Evidence
Another method used to reduce hallucinations used by many production applications is to provide the LLM with evidence to reason through. This can be done simply by inputting an article into the prompt as evidence, or in more sophisticated ways by retrieving relevant context from a vector database for retrieval-augmented generation (RAG).
Without Evidence Here we can see in an example without evidence, the LLM confidently answers with a fabricated number.
# Prompt:
What was Matterport's subscriber base on the precise date of May 31, 2020?
# Response:
It was 100,000.
With Evidence Below we can see the the LLM performs significantly better with evidence. This prompt combines some of the techniques above, incorporating aspects of XML tag separators, prompt templates, chain of thought (CoT) and providing the model with an ’exit option’.
# Prompt:
<question>
What was Matterport's subscriber base on the precise date of May 31, 2020? Please read the below document.
</question>
<instructions>
Then, in tags, pull the most relevant quote from the document and consider whether it answers the user's question or whether it lacks sufficient detail. Then write a brief numerical answer in tags. Only answer if you know the answer with certainty.
<instructions>
<document>
{document}
</document>
# Response:
<evidence>On May 31, 2020, Matterport reached 1 million subscribers.
By the end of the year, the company reached 2 million subscribers.
<evidence>
<answer>
1 million subscribers
<answer>
Avoiding Bias
LLMs Tend to Favor the Second Option When Given a List
An interesting pattern observed in LLM behavior is their tendency to favor the second option when presented with a list of choices. This can likely be attributed to the training data, which includes a wide array of internet sources such as search results, forums, and articles.
In situations where no option is clearly dominant, the model often defaults to the second choice, mirroring patterns commonly found in ranked lists or posts.
First Prompt
# Prompt:
Which of the following is a more positive movie review?
1. I really like this movie
2. This movie is great
# Response:
This movie is great
Second Prompt
# Prompt:
Which of the following is a more positive movie review?
1. This movie is great
2. I really like this movie
# Response:
I really like this movie
Getting Reliable Structured Data
Obtaining consistent and reliable output from an LLM that can be programmatically processed in production environments is often a challenge. This issue is common among LLM users, which is why companies like OpenAI and Anthropic have introduced a structured output feature known as ‘JSON Mode.’
This feature allows developers to receive responses in a predictable format by specifying JSON parameters when calling the API, and by incorporating JSON formatting directly into the prompt. This structured approach streamlines the integration of LLM outputs into applications.
# Prompt:
Make a time table for each hour of the day. Describe your task in detail. Return your answer with the following JSON format:
{
”12am”: [],
”1am”: [],
...
”11pm”: []
}
// Output
{
”12am”: ["Sleep"],
”1am”: ["Sleep"],
// Other entries
”11pm”: ["Get ready for Bed"]
}
Prompt Chaining
Rather than refining a single prompt to achieve a ‘perfect’ response, an alternative approach is to use prompt chaining. Which involves asking the model to iteratively improve upon its own output. By breaking the task into smaller, manageable steps, you can guide the model toward a more accurate or refined answer through successive prompts.
# Prompt:
Name ten words that all end with the exact letters 'ab'.
Response
1. Cab 2. Dab 3. Grab 4. Gab 5. Jab 6. Lab 7. Nab 8. Slab 9. Tab 10. Blab
# Prompt:
Please find replacements for all ‘words’ that are not real words.
Since LLMs generate text by predicting the next word, asking the model to replace non-real words can sometimes result in it altering valid words. To address this, an effective strategy is to provide an ’exit option,’ allowing the model to return the original list if all the words are indeed valid. This approach minimizes unnecessary changes while ensuring accurate output.
# Prompt:
"Please find replacements for all ‘words’ that are not real words. If all the words are real words, return the original list."
Conclusion
In conclusion, prompt engineering is much more than just a set of tricks or shortcuts. It is a critical aspect of interacting with large language models (LLMs) right now, shaping how effectively these models serve their intended purposes across various industries.
From structuring prompts to managing temperature, few-shot learning, and even avoiding hallucinations, the way prompts are crafted can dramatically affect the output quality. As LLMs continue to evolve, the role of prompt engineering might become less important, however right now it is an an indispensable skill for anyone building LLMs-based applications to ensure accuracy, creativity, and alignment with specific use cases.
Acknowledgement
A lot of the content of this article is based on Anthropic’s Prompt Engineering Course with the visualizations from Emmanuel Ogebe.